AI 최강자 등극 구글 '제미나이', GPT-4와 비교해 보니

[서울=뉴스핌] 최원진 기자= 구글이 오픈AI의 최신 생성형 인공지능(AI) 거대언어모델(LLM) 'GPT-4'를 능가하는 자체 모델 '제미나이(Gemini) 1.0'을 6일(현지시간) 공개해 화제다.
지난해 11월 챗GPT로 생성형 AI의 미래를 제시한 오픈AI가 기술 최강 자리를 굳건히 지킬 것이란 예상이 GPT-4 출시 후 불과 약 9개월 만에 깨진 것이다. 구글 제미나이가 AI 업계의 치열한 개발 경쟁에 다시 한번 불을 지폈다.
 |
◆ 제미나이의 강점은 '멀티 플레이어'
제미나이는 3가지 버전으로 나온다. 구글이 지금까지 내놓은 것 중 가장 강력한 LLM이자 데이터센터와 기업용 모델인 '제미나이 울트라', 구글의 AI 챗봇 '바드'의 모델인 '제미나이 프로', 스마트폰 등 모바일 기기에서 사용 가능한 컴팩트한 사이즈의 '나노'다.
제미나이 프로는 제품 공개한 이날 바로 바드에 탑재됐다. 제미나이 프로가 적용된 바드는 170개 이상 국가 및 지역에서 영어로 제공되며, 향후 서비스 확장 및 새로운 지역과 언어도 지원될 예정이다.
'제미나이 울트라'는 내년 초 '바드 어드밴스트'라는 이름으로 바드에 장착되며, '제미나이 나노'는 구글이 지난 10월 공개한 최신 스마트폰인 '픽셀8 프로'에 탑재된다.
구글은 제미나이가 "선천적"(natively)으로 멀티모달(Multi-Modal·다중모드) AI 모델이라고 소개한다. 멀티모달은 말그대로 텍스트뿐만 아니라 이미지, 동영상 등 비언어 입력값도 이해해 응용할 수 있는 '멀티 플레이어'다.
오픈AI가 이미지 생성 AI '달리'(DALL-E), 음성 인식 AI '위스퍼'(Whisper)를 각각 개발한 방식과 달리 구글은 애초부터 텍스트·이미지·오디오 등 다양한 데이터로 제미나이를 훈련해왔다는 것이다.
 |
| 제미나이가 학생의 물리학 문제를 풀이해주는 예시. [사진=구글 딥마인드 제공] |
특히 제미나이는 이미지와 동영상을 이해한 데이터를 응용하고 상호 작용하는 데 강점을 보인다.
예컨대 한 학생이 물리학 문제를 풀이하는 과정을 펜으로 쓴 이미지를 교사가 제미나이 프롬프트에 넣어 문제 풀이 과정에 어떤 부분이 틀렸는지 질문하면 제미나이는 정확히 문제의 정답과 학생의 손 글씨를 이해해 잘못된 문제 풀이 과정을 수정해 준다.
구글 딥마인드는 "제미나이가 이미지 속 텍스트를 이해하는 것을 넘어 교사가 어떻게 문제를 다르게 설정했는지 등을 이해해야 가능하다"고 설명했다. 제미나이는 오답 풀이 뿐만 아니라 학생이 틀린 유형의 다른 연습 문제도 제공해 교육 환경에서의 활용도가 높다는 게 자체 평가다.
이 밖에 제미나이는 동영상 속 언어를 감지해 번역 자막을 달아주고, 동영상 속 상황을 이해해 질문에 답할 수 있다.
◆ 32개 벤치마크 테스트 중 30개, 최고 성적
이미지와 영상의 이해부터 수학적 추론까지 가능한 제미나이 울트라가 업계에서 LLM 연구개발 평가 시 널리 사용되는 학술 벤치마크 기준 32개 가운데 30개 항목에서 GPT-4를 뛰어넘는 성적을 기록했다.
구체적으로 제미나이 울트라는 텍스트와 추론 벤치마크 부문 12개 중 10개, 이미지 이해 부문 9개 중 9개, 동영상 이해 벤치마크 6개 중 6개, 음성 인식 부문 5개 중 5개에서 GPT-4보다 높은 신기록을 썼다.
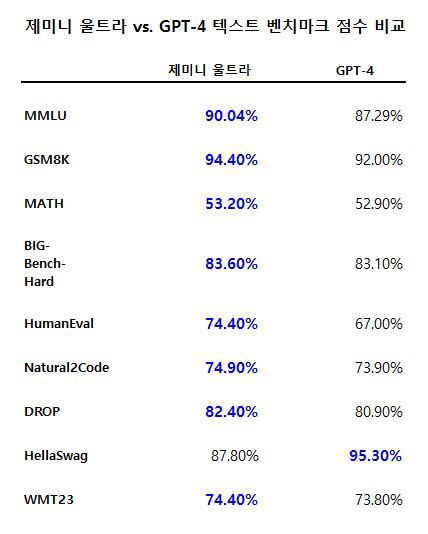 |
특히 대규모 다중작업 언어 이해(MMLU) 벤치마크에서 제미나이 울트라는 90% 이상의 정답률을 기록했다.
MMLU는 수학, 물리학, 역사, 법률, 의학, 윤리 등 57개의 주제를 복합적으로 활용해 지식과 문제 해결 능력을 평가하는 대표 격 LLM 벤치마크다.
구글 딥마인드는 제미나이 울트라의 MMLU 점수가 GPT-4의 86.4%를 앞선 것에서 나아가 AI 모델로는 최초로 인간 전문가 점수인 89.8%를 뛰어넘었다고 밝혔다.
이 밖에 여러 단계의 추론을 요구하는 여러 문제 해결 능력을 평가하는 빅 벤치 하드(BIG-Bench-Hard)와 독해력 벤치마크인 DROP에서 각각 80%가 넘는 점수로 GPT-4를 능가했다.
WMT23 벤치마크는 LLM의 번역 능력을 평가한다. 제미나이 울트라는 74.40%로 GPT-4보다 번역 능력이 우수했다.
다만 일상에 필요한 상식 추론 능력을 보는 헬라스웨그(HellaSwag) 벤치마크에서는 제미나이 울트라가 GPT-4에 못미쳤다.
 |
제미나이 울트라의 이미지 이해 능력은 GPT-4 보다 뛰어났다.
과학, 기술, 인문 과학, 음악 등 6개 핵심 부문 대학교 시험과 교과서에서 수집된 차트, 표, 악보 이미지를 이해하는 능력을 평가하는 다소 새로운 벤치마크인 MMMU에서 제미나이 울트라는 59.4%를 기록, GPT-4를 앞섰다.
이미지를 보고 이해해 관련 질문에 답할 수 있는 능력을 확인하는 VQAv2 벤치마크와 서류상 이미지를 이해하는 능력을 보는 DocVQA, 그래프 등을 보고 수학적 추론 능력을 보는 매스 비스타(MathVista) 벤치마크에서도 GPT-4 보다 좋은 성적을 거뒀다.
AI 모델의 동영상 이해를 평가하는 벤치마크들에서도 제미나이 울트라는 두각을 보였다.
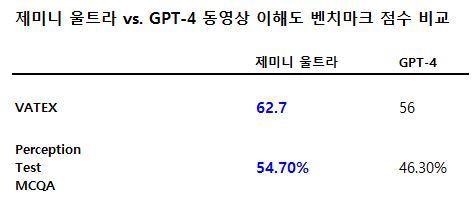 |
영상 속 상황을 텍스트로 옮기는 능력을 평가하는 VATEX 벤치마크와 영상과 관련된 질문에 답해 전반적인 영상 이해도를 평가하는 인식 테스트 MCQA 벤치마크 모두 GPT-4를 뛰어넘었다.
이밖에 중국어 텍스트로 영상 속 상황을 옮기는 능력을 평가하는 VATEX ZH, 영어로 복잡한 요리 과정이 담긴 영상을 텍스트로 옮기는 YouCook2 등 여러 벤치마크에서도 높은 성적을 거뒀다.
제미나이 프로의 음성 인식 이해도도 우수했다. 21개 언어의 음성을 인식해 텍스트로 변환하는 능력을 평가하는 CoVoST 2 벤치마크에서 제미나이 프로는 40.1을 기록, 오픈AI의 음성 인식 AI 모델 '위스퍼' 버전 2(v2) 보다 10 이상 높았다.
 |
62개 언어로 음성 인식 여부를 확인하는 FLEURS 벤치마크에서도 제미나이 프로는 7.6%를 기록, 위스퍼 v3 보다 월등했다. FLEURS는 AI 모델이 음성 인식 정확도를 측정하는 테스트로 점수가 낮을 수록 인식 오류가 적다는 의미다.
이밖에 제미나이는 파이선(Python), 자바(JAVA), C++, Go 등 세계에서 널리 사용되는 프로그래밍 언어로 코드를 이해하고 생성할 수 있다.
코딩 작업 성능을 평가하는 업계 표준인 휴먼이발(HumanEval) 벤치마크에서 제미나이 울트라는 74.4%를 기록해 GPT-4(67.0%)를 능가했다. 파이썬 코드 생성 능력을 평가하는 내추럴2코드(Natural2Code) 벤치마크에서도 GPT-4 보다 1%포인트(p) 높은 74.9%를 기록했다.
 |
| [사진= 구글 홈페이지] |



